I just published a new version of my open source C# Zoro library in Github and Nuget.org.
Zoro is a data anonymization (also called “masking”) utility. It fetches data from databases and files, anonymizes them according to the configuration provided and uses the anonymized data to create a new file or create/modify database data (using INSERTs, UPDATEs etc).
In the new version, 3.x, the library is still based on DotNet Standard 2.1, which offers the widest possible compatibility. The command line utility and the test project have been upgraded to DotNet 10.
But the most important new feature is that, apart from structured data data such as CSVs and JSONs, Zoro now starts supporting semi-structured data in the form of Office documents. Version 3.0 started with document (.docx) support. Version 3.1 supports spreadsheets (.xlsx). Presentations (.pptx) are coming soon!
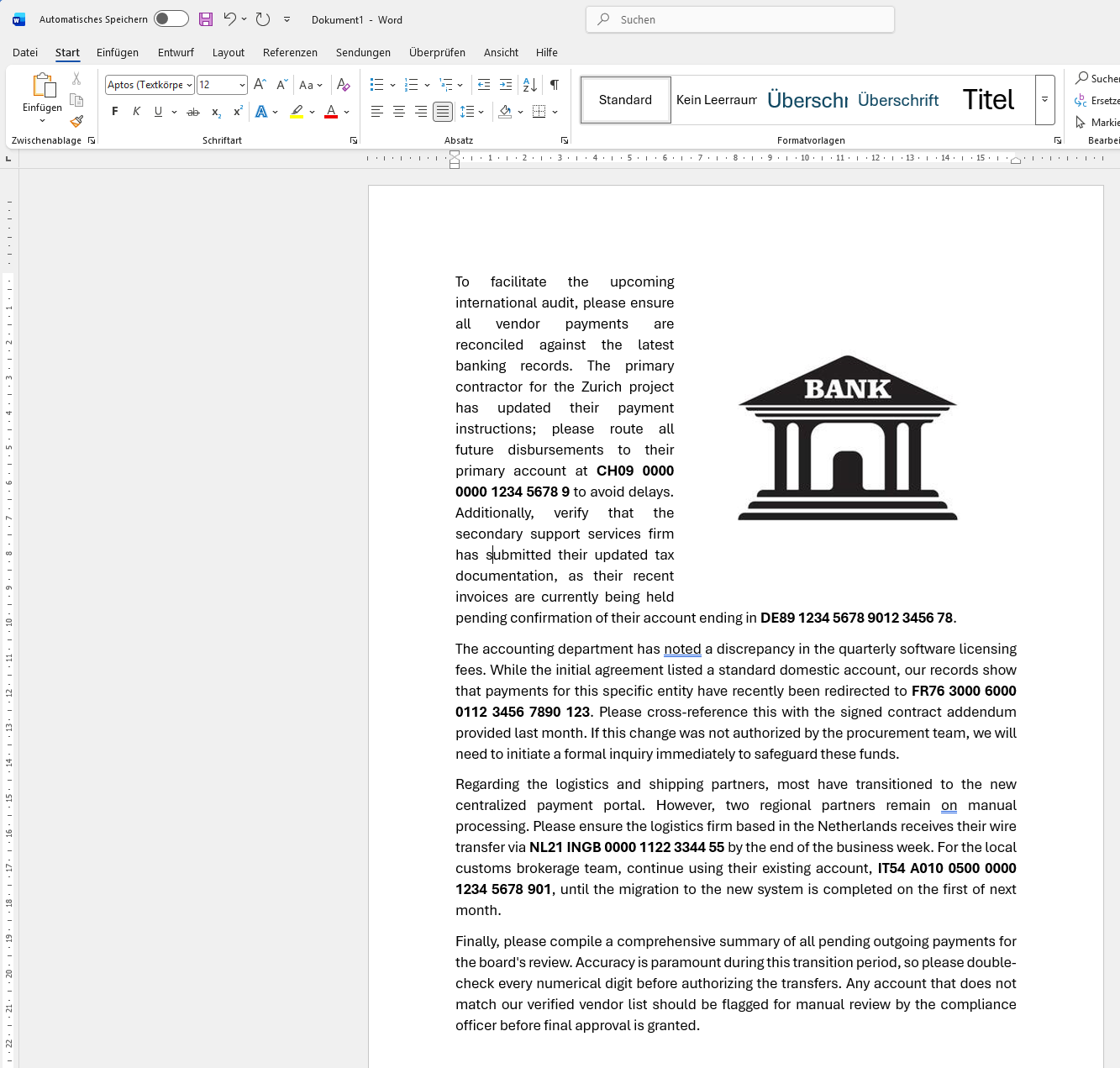
For example, let’s say you want to anonymize IBANs is such a document:
In order to anonymize the above data, your config could look like this:
Remember the days when people were proclaiming that Scrum can cure cancer? Not as a joke but, like, seriously? Ah, those were the days 🤦♂️
Of course, that was all a bunch of… trying to sound professional here… nonsense. Yes, it helps if teams of all disciplines can organize their work efficiently. But, I’m sure you’ll be surprised to hear, their work organization before scrum wasn’t exactly a pile of papers thrown around randomly.
After the initial years of agile and scrum hype, the inevitable realization kicked in. That’s not to say scrum isn’t a useful way of organizing work; it definitely is. But parts of it were brought to reality. And a big one was story points.
A terrible AI-generated image of hands, with varying number of fingers, holding cards with Fibonacci numbers. Yes, the “8” looks more like a Greek beta “β”.
And for good reason. People feel so strongly against them because they are hard to estimate. I’ve been in exhausting hours-and-hours-long meetings trying to get them right. Plus, do they really work? If you’ve spent more than fifteen minutes in a Scrum environment, you’ve heard the “Classical Scrum” lecture: “Story points measure complexity, not time!” It’s a beautiful, noble sentiment. It’s also, quite frankly, a load of… trying to sound professional here… nonsense.
The Great Divide
On one side, you have the Dev team, trying to explain that a “3” is like a medium-sized cat: “it’s not about how long it takes to wash the cat, it’s about how many claws the cat has“.
On the other side, you have literally everyone else—Stakeholders, Project Managers, and probably their puppies—who only want to know one thing: “When is this going to be finished?”
You can explain Fibonacci sequences until you’re blue in the face, but the business runs on calendars, not abstract integers. We techies need to answer the “when” question without losing our souls -or our weekends.
So, I stopped fighting human nature. Instead, I started using a mind trick.
The Trick: “Days” That Aren’t Days (But are) (Well, kind of) (But not really) (Eh, sort of)
Here is the system I use to bridge the gap between devs and, for a lack of better term, the real world.
I tell my team we are estimating effort in sizes: Small, Medium, and Large. But—and here’s the trick—I tell them to estimate those sizes using “Days of Effort.”
These are not the story points you’re looking for
For a 3-week sprint (15 working days), I only allow three choices:
Small: 2 “Days”
Medium: 5 “Days”
Large: 15 “Days”
Wait, a 15-day story in a 15-day sprint? Yes. Because we all know that “Large” actually means “This is the only thing I am doing, and I’ll probably still be screaming at my IDE on Friday afternoon.”
The “Phase 2” Maneuver (Handling the Unfinished)
Sprints are messy. When the clock runs out, i.e. on the last day of the sprint, and items aren’t done, we don’t just “carry them over” and pretend nothing happened. We follow two rules:
The “Zero Progress” Rule: If no work was done during the sprint, the item moves to the next sprint as-is.
The “Downgrade” Rule: If some work was done, we downgrade the effort by one grade (15 becomes 5, 5 becomes 2, 2 stays 2) and set it to “Done”. We then create a “Phase 2” copy of the ticket for the next sprint with the effort that we estimate is remaining -can be anything from Small to Large. If the item (usually a PBI) has unfinished tasks, we change their parent to the new PBI and move them to the next sprint as well.
Note: we only estimate PBIs, not Tasks. In our board, Tasks are welcome and encouraged, but not mandatory.
At the end of the sprint, we look at what was actually finished. We take the average of the last three sprints, and that is our Velocity. If our average is 90 “effort-days”, we don’t commit to 150. We aren’t heroes; we’re mathematicians (well, the good kind).
Why Does This Work? (The Science of Being Wrong)
To be clear, I’m not lying to anyone. I tell my team, the stakeholders, and their puppies (yes I actually tried once; the puppy seemed to nod in agreement though she may have thought I’ll give her a treat and was promptly disappointed) exactly how this works. And yet, it still works. Why?
No idea, I just want my treat
Because developers are notoriously terrible at estimation, but—and this is key—we are consistently terrible.
Think of it as the Mindset Coefficient μ.
When a developer estimates the effort E required to complete a piece of work, the real effort R can be calculated by:
The value of μ depends on the specific people in the room. As long as the team remains the same, μ stays remarkably constant. They might think they’re estimating “days,” but they’re actually providing a consistent unit of “their own personal version of time.”
No, not this version of time
By using the downgraded “Phase 2” tickets and the 3-sprint average, we are effectively solving for μ using real-world data. We aren’t trying to force developers to be “correct”; we are calibrating our planning to account for their specific brand of optimism. The famous developer’s optimism is the reason why μ is always always always >1.
An Example
Let’s say we start the sprint with 4 PBIs:
PBI S1 and S2 are estimated at 2 “days”.
PBI L3 is estimated at 15 “days”.
PBI M4 is estimated at 5 “days”.
In the middle of the sprint, as it often happens, there’s an urgent issue. So we add a PBI M5 which we estimate at 5 “days”.
At the end of the sprint, we’ve finished S1, M4 and M5. So we set them to done (obviously this can be done earlier, doesn’t have to be on the last day).
For S2, we set it to Done. It’s at 2 “days” so this stays the same. We then create a copy “S2 – Phase 2” which we estimate at 2 “days” for the remaining work and assign it to the next sprint.
For L3, we set it to Done. It’s at 15 “days” so we change it to 5 (downgrade by one grade, remember?). Note that the change, in Azure Devops at least, has to be made before setting it to Done. We then create a copy “L3 – Phase 2” which we estimate at 5 “days” for the remaining work and assign it to the next sprint.
So what’s our velocity? For this sprint it’s:
Finished S1, M4 and M5 = 2 + 5 + 5 = 12 “days”.
Unfinished S2 and L3 = 2 + 5 = 7 “days”.
Total 19 “days” of effort.
Of course that’s for a single sprint; we need to average over the last 3, but even if it’s the first sprint of the team, it’s still a useful indicator.
The Result
The team stops sweating the “Complexity vs. Time” debate. Estimation becomes an easy exercise because the options are both relatable and limited. The business gets a velocity they can actually use to project a release date.
It’s a Jedi mind trick because even though everyone knows the “days” aren’t literal, their brains start treating them that way. They think in days, we plan in days, and the “Mindset Coefficient” handles the translation to reality.
Want more “honestly-it-works” advice? Check out my previous post on How to store secrets the right way. Because your API keys shouldn’t be as public as your estimation errors 😊
So the other day I’m doing a code review in an enterprise application. The goal was to switch the data storage from SharePoint Online Lists to Azure SQL database tables. “Easy,” I thought. “It’s just a change in the Data Access Layer (DAL)”.
Long story short, I started reviewing the source code and… wasn’t amused. This was (a small sample of) the problem:
I mean, dear programmer, look. You want to add a directory related to an employee. I get it. But why is the PnPContext sitting there in the method signature like an uninvited guest at a wedding?
This is what we call a “Leaky Abstraction.” Your Data Access Layer (DAL) is leaking its internal stuff all over your business logic. Depending on the case, today it’s Sharepoint, tomorrow it’s SQL Server, and the day after it’s a carrier pigeon. If your business logic knows in what kind of medium your data is stored in, you’re in for a world of hurt.
The Problem: When your DAL tells too much
The core issue is coupling. When you pass an SqlConnection, an SqlDataReader, or a SharePoint PnPContext directly into your business services, you are essentially tattooing your data vendor onto your forehead.
If you leak these details:
You can’t switch providers: Moving from SQL to SharePoint to Oracle to clay tablets becomes a “rewrite everything” project instead of a “change one class” task.
Testing is a nightmare: You can’t unit test your business logic without a Sharepoint, SQL Server etc. running, because your methods demand a real connection.
Code smell: Your business logic should care about what is being saved, not how the connection string is formatted.
The “Wrong” Way: The Leaky Bucket
Take a look at this example. It’s the kind of code that works fine during development, works fine in UAT, but makes you want to retire when requirements change.
using (SqlConnectionconn=newSqlConnection(connectionString))
{
conn.Open();
// Why is my Business Logic managing SQL connections?!
varcmd=newSqlCommand("SELECT * FROM Invoices WHERE Id = @id", conn);
cmd.Parameters.AddWithValue("@id", invoiceId);
// ... process logic ...
}
}
Did you notice? The business logic is doing the heavy lifting of database management. If the boss says “We’re moving to an OData API,” you have to touch every single file in your project.
Ugh I can’t even
The Solution: The Repository Pattern
So how do you do this correctly?
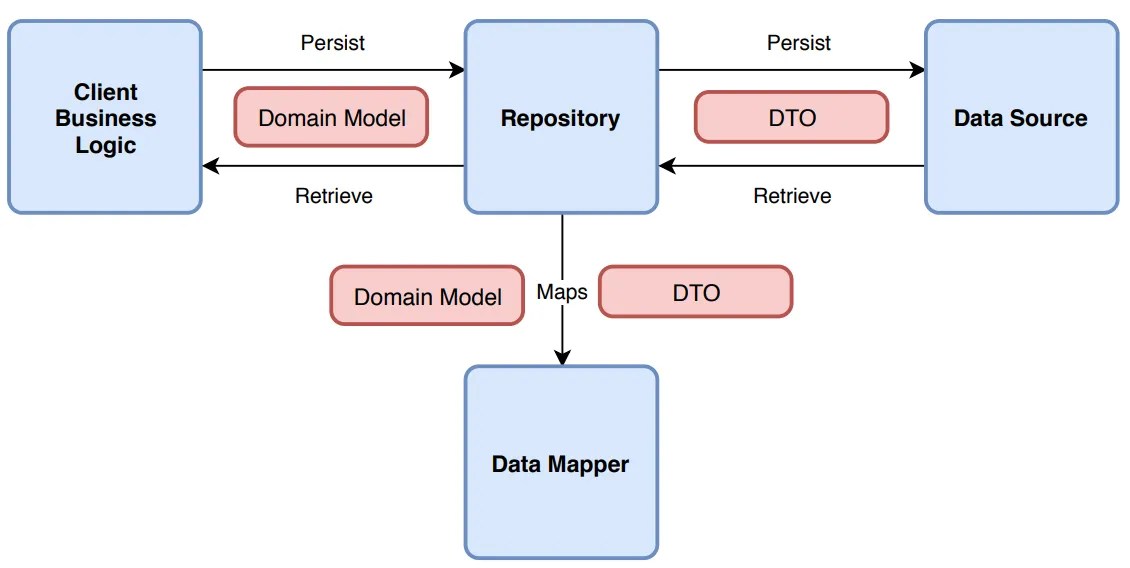
First of all, it’s a good idea not to reinvent the wheel. You can use the Repository Pattern. Think of a Repository as a mediator between the domain and the data mapping layers. It acts like an in-memory collection of domain objects.
Your business logic should talk to an Interface, and that interface should speak the language of your business (Invoices, Customers, Files), not the language of your storage (Tables, Blobs, Transactions).
The Refactored Way: Clean and Dry
Let’s fix that mess. First, we define what we want to do, without mentioning the data storage medium. Here’s an example of an invoice processor:
Notice how the interface uses only basic types (such as int, string etc) or our clean business objects. It should NEVER use data store-specific types, such as DataRow.
3. The Business Logic (the right way)
Now, the business logic is blissfully ignorant. It’s like a person ordering a pizza who doesn’t care if the oven is electric or wood-fired.
InvoiceService.cs
C#
publicclassInvoiceService
{
privatereadonlyIInvoiceRepository_repo;
publicInvoiceService(IInvoiceRepositoryrepo)
{
_repo=repo; // Dependency Injection!
}
publicvoidProcessInvoice(intinvoiceId)
{
varinvoice=_repo.GetById(invoiceId);
// Do actual business work here...
_repo.Save(invoice);
}
}
3. Data layer implementation
Now, you can have a SqlInvoiceRepository for today, and a SharePointInvoiceRepository for tomorrow. The rest of your app won’t even notice the difference. All they need is to implement IInvoiceRepository.
Final Thoughts
It’s tempting to just “pass the connection” because it’s faster. It’s easy to forget that code lives longer than infrastructure.
But in any case, be careful to consider your future self (not to mention others that might maintain your code). Is your software supposed to grow? A good place to start is decoupling.
Whatever you do, PLEASE PLEASE PLEASE DON’T LEAK YOUR DAL DETAILS.
As with the script cheat sheet, that’s not a post, at least in the classical sense 😊 Rather it’s a collection of knowledge that I will keep updating, for me to find easily.
Web-trained: Most large models (Common Crawl, web scrapes)
Curated: Models trained on filtered, high-quality datasets
Domain-specific: Models trained on specialized corpora
Synthetic: Models incorporating AI-generated training data
Architecture Categories
1. Transformer-based: Uses attention mechanisms to process sequences in parallel. Self-attention allows the model to weigh relationships between all tokens simultaneously.
Processes all positions simultaneously with O(n2) complexity.
2 . Recurrent (LSTM/GRU): Processes sequences step-by-step using memory states. Information flows through hidden states that capture context from previous tokens.
Hidden State Update: ht=f(Whht−1+Wxxt+b)
LSTM Gates:
Forget: ft=σ(Wf⋅[ht−1,xt]+bf)
Input: it=σ(Wi⋅[ht−1,xt]+bi)
Output: ot=σ(Wo⋅[ht−1,xt]+bo)
Sequential processing with O(n) complexity
3. Convolutional: Applies sliding filters across text sequences to detect local patterns and features, similar to image processing.
1D Convolution: (f∗g)[n]=∑mf[m]⋅g[n−m]
Feature Maps: yi,j=ReLU(∑kwk⋅xi+k,j+b)
Local pattern detection with sliding windows
4. Hybrid: Combines multiple architectures (e.g., transformer + CNN) to leverage different strengths.
Or parallel processing: Output=α⋅Trans(x)+β⋅RNN(x)
Key difference: Transformers use parallel attention (O(n2) memory), RNNs use sequential states (O(n) memory), CNNs use local convolutions.
Main pros & cons:
Transformer-based
Pros: Fast parallel processing, excellent at understanding context
Cons: Memory-hungry, struggles with very long texts
Recurrent (LSTM/GRU)
Pros: Memory-efficient, good at sequential patterns
Cons: Slow training, forgets distant information
Convolutional
Pros: Fast, good at detecting local patterns
Cons: Limited long-range understanding, less flexible
Hybrid
Pros: Combines strengths of multiple approaches
Cons: More complex, harder to optimize
In layman’s terms:
Transformers is reading the whole page at once
Recurrent is reading word-by-word while taking notes
Convolutional is scanning for specific phrases, and
Hybrid is using multiple reading strategies together.
Training Approach Categories
– Autoregressive: Predicts the next token given previous tokens. Trained left-to-right on text sequences.
– Masked Language Modeling: Randomly masks tokens in text and learns to predict them using bidirectional context from both sides.
– Encoder-Decoder: Encodes input into representations, then decodes to generate output. Useful for translation and summarization tasks.
– Reinforcement Learning from Human Feedback (RLHF): Fine-tunes models using human feedback as rewards. Trains the model to generate responses humans prefer through reinforcement learning.
Main pros & cons:
Autoregressive (GPT-style)
Pros: Great at creative text generation, coherent long-form writing
Cons: Can’t “look ahead” in text, slower for some tasks
Masked Language Modeling (BERT-style)
Pros: Understands context from both directions, excellent for comprehension
Cons: Poor at generating new text from scratch
Encoder-Decoder (T5-style)
Pros: Flexible for many tasks, good at text-to-text transformations
Cons: More complex architecture, requires more computational resources
Reinforcement Learning from Human Feedback (RLHF, ChatGPT/Claude-style)
Pros: Produces helpful, harmless responses aligned with human preferences
Cons: Expensive to train, can be overly cautious or verbose
In layman’s terms:
Autoregressive is like writing a story word-by-word
Masked is like fill-in-the-blank exercises
Encoder-Decoder is like translation between languages, and
RLHF is like having a human tutor guide the AI’s responses.
This is the easy way. And it works… unless the log file is big, meaning, more than a few GB. In this case, trying to fit the whole file in memory (which Get-Content does) is going to blow up your system.
So, what do you do? You stream. No, not like Netflix. Well, kind of:
Contrary to “normal” languages like C# or Java, Powershell is not a compiled language, but rather an interpreted one. This means that instead of using a compiler, the Powershell Scripting Runtime Environment reads and executes the code line-by-line during runtime.
That has well known advantages -for example, you can change code on the spot- and disadvantages -e.g. performance. But one major disadvantage is that there are no compiler errors. That means that if you forget to close a parenthesis or a bracket, nothing works. It’s the silliest of mistakes but still crashes everything.
With Powershell being used in non-interactive environments, like Azure Functions, it’s becoming all the more important to guard against such errors.
Fortunately, there is a solution for this. Microsoft has published the PSScriptAnalyzer module (link) which includes the Invoke-ScriptAnalyzer (link) command. Running this against your code, you get a list of warnings and errors:
The best things is, you can include this in your CI/CD pipelines, e.g. in Azure Devops or Github.
So here’s an example of an Azure Devops pipeline task that checks for ParseErrors (meaning, the script is not readable) and stops the build in case such an error is found:
#
# Source: DotJim blog (http://dandraka.com)
# Jim Andrakakis, October 2024
#
- task: PowerShell@2
displayName: Check for Powershell parsing errors
inputs:
targetType: 'inline'
errorActionPreference: 'stop'
pwsh: true
script: |
Install-Module -Name PSScriptAnalyzer -Scope CurrentUser -Force
Write-Host 'Performing code analysis using Microsoft Invoke-ScriptAnalyzer'
$findings = Invoke-ScriptAnalyzer -Path '$(System.DefaultWorkingDirectory)' -Recurse -Severity ParseError,Error
$findings | Format-List
if (($findings | Where-Object { $_.Severity -eq 'ParseError' }).Count -gt 0) { Write-Warning "Parse error(s) were found, review analyser results."; exit 1 }
While Azure Devops is widely used, Microsoft’s backup solutions are surprisingly thin. With people depending on it, individuals and enterprises alike, you’d expect a bit more.
There are various tools around, but here’s my version in the form of a Powershell script. What it does is:
Connects to a specific Azure Devops project and repo.
Lists all branches, downloads them using git and zips them.
The zip, one for every branch, is named Backup_yyyy-MM-dd_branch.zip.
I just published the first version of my open source C# library named Dandraka.FuzzySubstringSearch in Github and Nuget.org.
FuzzySubstringSearch is intended to cover the following need: you need to know if a string (let’s call it Target) contains another string (let’s call it Searched). Obviously you can do this using String.Contains(). But if you need to account for spelling errors, this doesn’t work.
In this case, you need what is usually called “fuzzy” search. This concept goes like this: matching is not a yes or no question but a range. – If the Target contains the Searched, correctly, we’re at one end of the range (say, 100%). – If Target contains no part of Searched we’re at the other end (0%). – And then we have cases somewhere in the middle. Like if you search inside “Peter stole my precius headphones” for the word “precious”. That should be more than 0 but less than 100, right?
Under this concept, we need a way to calculate this “matching percentage”. Obviously this is not new problem. It’s a problem Computer Science has faced since decades. And there are different algorithms for this, like the Levenshtein distance, Damerau–Levenshtein distance, the Jaccard index and others.
But the problem is, these algorithms compare similar strings. They don’t expect that the Target is much larger than Searched.
Enter N-grams. N-grams are, simply put, pieces of the strings (both Target and Searched). N refers to the size of the pieces: 2-grams means the pieces are always 2 characters, 3-grams means 3 characters etc. You break Target and Searched into pieces (the N-grams), check how many are matching and divide by how many pieces Searched has.
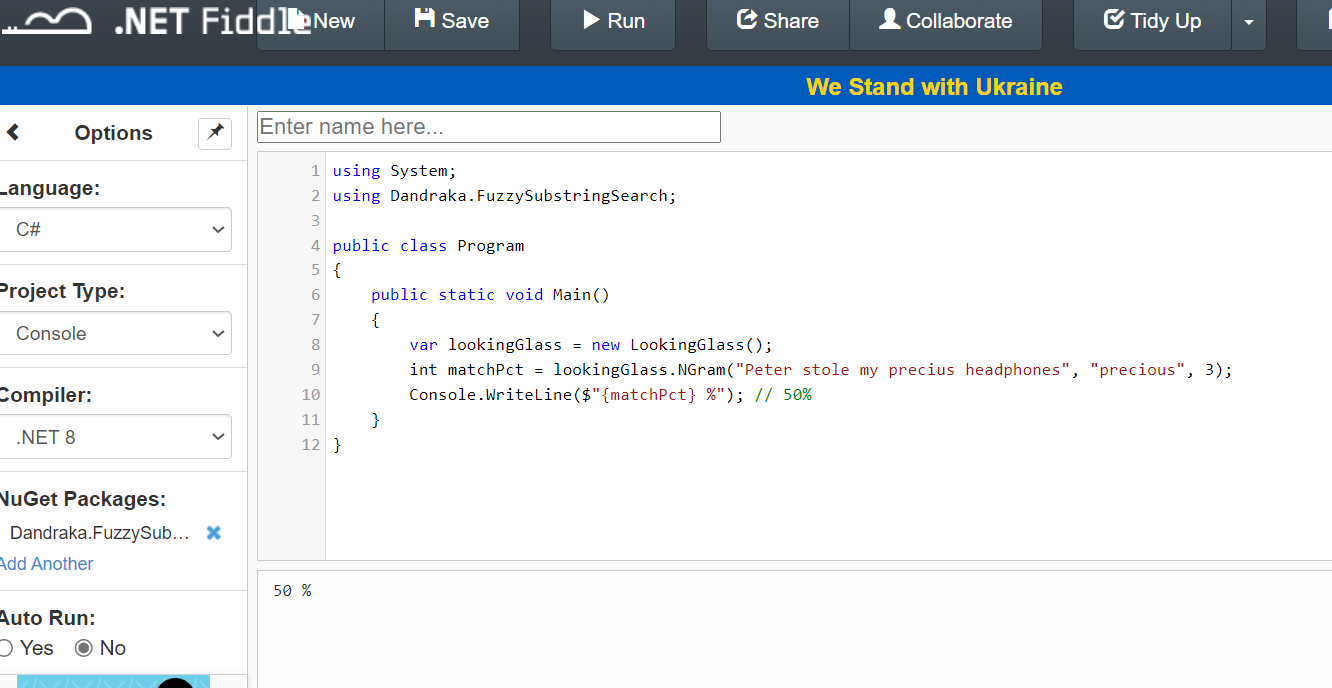
Let’s do an example: we’re searching inside “Peter stole my precius headphones” for “precious”.
Here’s how it goes. Let’s use 3-grams. Target has the following 3-grams:
Pet
Peter stole my precius headphones
ete
Peter stole my precius headphones
ter
Peter stole my precius headphones
er(space)
Peter stole my precius headphones
r(space)s
Peter stole my precius headphones
(space)st
Peter stole my precius headphones
(etc etc)
(etc etc)
pre
Peter stole my precius headphones
rec
Peter stole my precius headphones
eci
Peter stole my precius headphones
ciu
Peter stole my precius headphones
ius
Peter stole my precius headphones
(etc etc)
(etc etc)
And Searched has the following 6:
pre
precious
rec
precious
eci
precious
cio
precious
iou
precious
ous
precious
How many of the Searched 3-grams can you find in Target? The following 3: pre, rec, eci. So the percentage is 3 found / 6 total = 50%. And if you use 2-grams instead of 3-grams, the percentage increases to 71% since more 2-grams are matching. But, importantly, you “pay” this with more CPU time.
Here we’re not going to talk about this kind 😊 But that doesn’t mean it’s not important.
It happens quite often that a script you need to run needs access to a resource, and for this you need to provide a secret. It might be a password, a token, whatever.
The easy way is obviously to have them in the script as variables. Is that a good solution?
If you did not answer NO THAT’S HORRIBLE… please change your answer until you do.
Ok so you don’t want to leave it lying around in a script. You can ask at runtime, like this:
$token = Read-Host -Prompt "Please enter the connection token:" -AsSecureString
That’s definitely not as bad. But the follow up problem is, the user needs to type (or, most probably, copy-paste) the secret every time they run the script. Where do the users store their secrets? Are you nudging them to store it in a notepad file for convenience?
In order to keep our systems safe, we need a way that is both secure and convenient.
That’s why using the Windows Credential Manager is a much, much better way. The users only have to recover the secret once, and then they have it stored in a safe way.
Here’s an example of how you can save the secret in Windows Credential manager. It uses the CredentialManager module.
# === DO NOT SAVE THIS SCRIPT ===
# How to save a secret
# PREREQUISITE:
# Install-Module CredentialManager -Scope CurrentUser
$secretName = 'myAzureServiceBusToken' # or whatever
New-StoredCredential -Target $secretName -Username 'myusername' -Pass 'mysecret' -Persist LocalMachine
And here’s how you can recover and use it:
# How to use the secret
# PREREQUISITE:
# Install-Module CredentialManager -Scope CurrentUser
$secretName = 'myAzureServiceBusToken' # or whatever
$cred=Get-StoredCredential -Target $secretName
$userName = $cred.UserName
$secret = $cred.GetNetworkCredential().Password
# do whatever you need with the secret
Just for completeness, here’s an example of how to call a REST API with this secret. I imagine that’s one of the most common use cases.
Powershell offers a number of Active Directory (AD for short) commandlets to make an AD admin’s life a little easier. For example, if you need to get a list of members from an AD group, you can use something like:
The problem is that this doesn’t work everywhere. The ActiveDirectory module is not a “normal” one you can install with Install-Module; instead, you need to install a Windows feature, either from Control Panel or by using the Add-WindowsCapability commandlet.
But you don’t have to use this module. You can use something that’s available everywhere, the adsiSearcher type accelerator.
So here are a couple of scripts I came up with (credits where they’redue). The first searches through all groups, finds all the ones that match a string and lists all their members.