I just published a new version of my open source C# Zoro library in Github and Nuget.org.
Zoro is a data masking/anonymization utility. It fetches data from a database or a CSV file, masks (i.e. anonymizes) them according to the configuration provided and uses the masked data to create a CSV file or run SQL statements such as INSERTs or UPDATEs.
The new version, 2.0, has been converted to DotNet Standard 2.1 to take advantage of some useful DotNet features. The command line utility and the test project are written with DotNet Core 5.0.
The issue from 1.0.2, where the Nuget package did not contain the executables, has been corrected. The package now contains both a Win64 and a Linux64 executable. Since they are self-contained programs, no prior installation of DotNet is needed.
But the most important new feature is a new MaskType, “Query”. With this, the library can retrieve values from a database and pick a random one. In previous versions this was only possible with lists that were fixed in the XML (MaskType=List).
For example, let’s say you are masking the following data:
ID
Name
City
Country
1
ABB
Baden
CH
2
FAGE
Athens
GR
3
IKEA
Delft
NL
Table “customers”
In the database you might also have a table with cities and countries:
CityName
CountryCode
Zürich
CH
Geneva
CH
Bern
CH
Rethimno
GR
Chania
GR
Kalamata
GR
Gouda
NL
Geldrop
NL
Table “cities”
In order to anonymize the above data, your config could look like this:
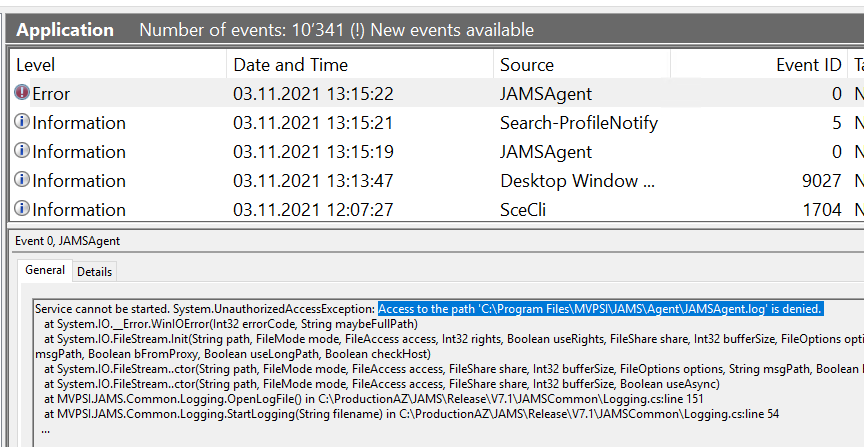
So the other day I’m troubleshooting a Windows Service that keeps failing on a server, part of a product we’re using in the company. Long story short, that’s what the problem was:
Access to the path 'C:\Program Files\whatever\whatever.log is denied'
I mean, dear programmer, look. You want to write your application’s logs as simple text files. I get it. Text files are simple, reliable (if the file system doesn’t work, you have bigger problems than logging) and they’re shown in virtually every coding tutorial in every programming language. Depending on the case, there might be better ways to do that such as syslog, eventlog and others.
But sure, let’s go with text files. Take the following example somewhere in the middle of a Python tutorial. Look at line 3:
import logging
logging.basicConfig(filename='app.log', filemode='w', format='%(name)s - %(levelname)s - %(message)s')
logging.warning('This will get logged to a file')
Did you notice? This code writes the log in the same place as the binary. It’s not explicitly mentioned and usually you wouldn’t give it a second thought, right?
To be clear, I don’t want to be hard on the writers of this or any other tutorial; it’s just a basic tutorial, and as such it should highlight the core concept. A professional developer writing an enterprise product should know a bit more!
But the thing is, these examples are everywhere. Take another Java tutorial and look at line 16:
package com.javacodegeeks.snippets.core;
import java.util.logging.Logger;
import java.util.logging.FileHandler;
import java.util.logging.SimpleFormatter;
import java.io.IOException;
public class SequencedLogFile {
public static final int FILE_SIZE = 1024;
public static void main(String[] args) {
Logger logger = Logger.getLogger(SequencedLogFile.class.getName());
try {
// Create an instance of FileHandler with 5 logging files sequences.
FileHandler handler = new FileHandler("sample.log", FILE_SIZE, 5, true);
handler.setFormatter(new SimpleFormatter());
logger.addHandler(handler);
logger.setUseParentHandlers(false);
} catch (IOException e) {
logger.warning("Failed to initialize logger handler.");
}
logger.info("Logging info message.");
logger.warning("Logging warn message.");
}
}
Or this Dot Net tutorial, which explains how to set up Log4Net (which is great!) and gives this configuration example. Let’s see if you can spot this one. Which line is the problem?
If you answered “7”, congrats, you’re starting to get it. Not using a path -this should be obvious, I know, but it’s easy to forget nevertheless- means writing in the current path, which by default is wherever the binary is.
So this works fine while you’re developing. It works fine when you do your unit tests. It probably works when your testers do the user acceptance testing or whatever QA process you have.
But when your customers install the software, the exe usually goes to C:\Program Files (that’s in Windows; in Linux there are different possibilities as explained here, but let’s say /usr/bin). Normal users do not have permission to write there; an administrator can grant this, but they really really really shouldn’t. You’re not supposed to tamper with the executables! Unless you’re doing some maintenance or an upgrade of course.
So how do you do this correctly?
First of all, it’s a good idea to not reinvent the wheel. There are many, many, MANY libraries to choose from, some of them very mature, like log4net for Dot Net or log4j for Java.
But if you want to keep it very simple, fine. There are basically two ways to do it.
If it’s a UI-based software, that your users will use interactively:
Create a directory under %localappdata% (by default C:\Users\SOMEUSER\AppData\Local) with the brand name of your company and/or product, and write in there.
You can get the localappdata path using the following line in Dot Net:
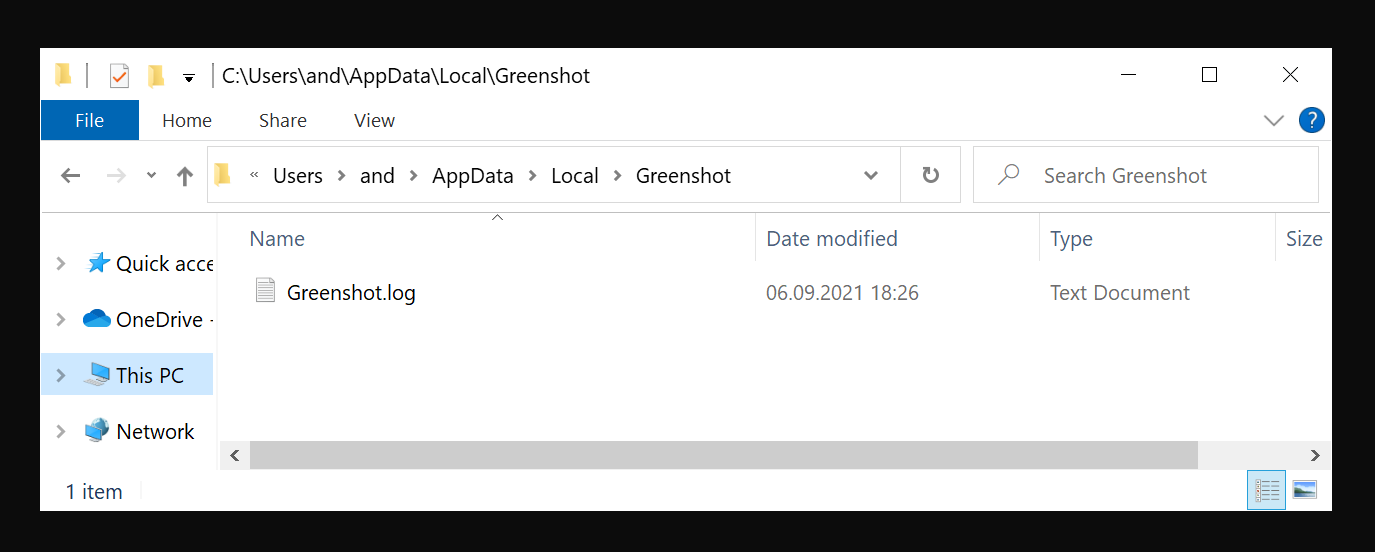
Take for example the screen-capturing software called Greenshot. These guys do it right:
If it’s a non-interactive software, like a Windows Service:
You can do the same as above, but instead of Environment.SpecialFolder.LocalApplicationData use Environment.SpecialFolder.CommonApplicationData, which by default is C:\ProgramData. So your logs will be in C:\ProgramData\MyAmazingCompany\myamazingproduct.log.
Or -not recommended, but not as horrible as writing in Program Files- you can create something custom like C:\MyAmazingCompany\logs. I’ll be honest with you, it’s ugly, but it works.
But in any case, be careful to consider your environment. Is your software supposed to run on Windows, Linux, Mac, everything? A good place to start is here, for Dot Net, but the concept is the same in every language.
And, also important, make your logging configurable! The location should be changeable via a config file. Different systems have different requirements. Someone will need the logs somewhere special for their own reasons.
But whatever you do, PLEASE PLEASE PLEASE DON’T WRITE WHERE THE BINARY IS. DON’T WRITE IN C:\PROGRAM FILES. IT. DOES. NOT. WORK.
I just published a new version of my open source C# Zoro(*) library in Github and Nuget.org.
Zoro is a data masking/anonymization utility. It fetches data from a database or a CSV file, and creates a CSV file with masked data.
The new version, 1.0.2, has been converted to DotNet Standard 2.0. The command line utility and the test project have been converted to Dotnet Core 5.0.
There is a known issue, not with the code but with the Nuget package. The description claims, as was intended, that the package contains not only the library but also the exe, which can be used as a standalone command line utility. But due to some wrong path in the Github Action, it doesn’t.
I’ll try to get that fixed in the next weeks. Until then, if you need the exe, please checkout the code and build with Visual Studio or Visual Studio Code.
(*) YES NOW I KNOW THIS IS MISSPELLED AND THE CORRECT SPELLING IS ZORRO, I DIDN’T WHEN I STARTED THE LIBRARY, SORRY!
Sooo you’re working in an enterprise and have to maintain an internal server. The security audit asks you to ensure all HTTP communications are encrypted, so you need to change to HTTPS. Boy is this SO not obvious. You’d think this should be quite easy by now, but there are A LOT of pitfalls in your way.
If you want the TL;DR version, to skip the explanation and go directly to the instructions, scroll directly to the Mandalorian below. No hard feelings, honest 😊
Mistake #1: Use a self-signed certificate
Many, many, MANY tutorials you’ll find online are written with a developer in mind, leaving the maintainer/admin as an afterthought -if that. So what they care about is having some certificate, any certificate, as long as it works on the developer’s PC.
But what this certificate says is basically “I’m Jim because I say so”.
Do I need to say that it won’t work for other PCs? Yes? Well surprise, it won’t.
Mistake #2: Get a certificate from your PC’s certificate authority
I don’t know how some people don’t understand that this, while being a bit more complex, it’s basically the same as #1. What this certificate says is “I’m Jim because someone else who is also Jim says so”.
Yeah, no, it won’t work.
Mistake #3: Get a certificate from a trusted certificate authority using only a server name (or an alias).
Now we’re getting more serious.
Getting a certificate from a trusted certificate authority (CA for short) is the right thing to do. The certificate you get then says “I’m Jim because someone else who you already trust says so”.
So if you get a certificate that verifies you’re, say, server web-ch-zh.xyz123.com or mysite.xyz123.com is good enough. Right?
Ummm…
IT DEPENDS.
If you run a website (e.g. https://www.xyz123.com) and want your HTTPS URL to work without giving a certificate warning that’s fine. You don’t need to do anything else. That’s why most tutorials that avoid the self-signed certificate mine stop here.
But remember, our scenario is that we’re working for an enterprise (a big company) and we’re maintaining an internal server. What that usually -not always, but a lot of the time- means is that communication to our server happens using different hostnames.
Let me give you my own example:
I run a service called Joint Information Module or JIM for short -that’s a totallyreal service name [1].
Another application uses the REST API of the service using the server name (ch-zh-jim-01) without the domain name (mycompany.local).
The service uses a queuing software that is installed on the same server. We want to use the same certificate for this as well. The JIM service accesses the queues via https://localhost (and a port number).
Now, if the certificate you got says “ch-zh-jim-01.mycompany.local ” and you try to access the server via https://ch-zh-jim-01, https://jim.mycompany.com, https://localhost or https://127.0.0.1, you’ll get a certificate error much like the following:
Also, the REST API won’t work. The caller will throw an exception, e.g. java.security.cert.CertPathValidatorException in Java or System.Security.Authentication.AuthenticationException in DotNet. You can avoid this by forcing your code to not care about invalid certificates but this is a) lazy b) bad c) reaaaaaaaaaaly bad, seriously man, don’t do this unless the API you’re connecting to is completely out of your control (e.g. it belongs to a government).
The correct way
So you need a certificate that is trusted and valid for all the names that will be used to communicate with your server. How do you do that? SIMPLEZ!
Generate a CSR (a certificate signing request, which is a small file you send to the CA) with the alternative names (SANs) you need. That’s what I’ll cover here.
Send it to a trusted CA
either the one your own company operates or
a commercial one (which you have to pay), say Digicert.
Get the signed certificate and install it on your software.
Important note: the CA you send the CSR to must support SANs. Not every CA supports this, for their own reasons. Make sure you read their FAQ or ask their helpdesk. Let’s Encrypt, a free and very popular CA, supports them.
Here I’ll show how you can generate a CSR, both in the “Microsoft World” (i.e. on a Windows machine) and in the “Java World” (i.e. on any machine that has Java installed).
A. Using Windows
Note that this is the GUI way to do this. There’s also a command line tool for this, certreq. I won’t cover it here as this post is already quite long, but you can read a nice guide here and Microsoft’s reference here. One thing to note though is that it’s a bit cumbersome to include SANs with this method.
Open C:\windows\System32\certlm.msc (“Local Computer Certificates”).
Expand “Personal” and right click on “Certificates”. Select “All tasks” > “Advanced Operations” > “Create Custom Request”.
In the “Before you begin” page, click Next.
In the “Select Certificate Enrollment Policy” page, click “Proceed without enrollment policy” and then Next.
In the “Custom Request” page, leave the defaults (CNG key / PKCS #10) and click Next.
In the “Certificate Information” page, click on Details, then on Properties.
In the “General” tab:
In the “Friendly Name” field write a short name for your certificate (that has nothing to do with the server). E.g. cert-jim-05-2021.
In the “Description” field, write a description, duh 😊
In the “Subject” tab:
Under “Subject Name” make sure the “Type” is set to “Full DN” and in the Value field paste the following (without the quotes): “CN=ch-zh-jim-01.mycompany.local, OU=IT, O=mycompany, L=Zurich, ST=ZH, C=CH” and click “Add”. Here:
Instead of “ch-zh-jim-01.mycompany.local” enter your full server name, complete with domain name. You can get it by typing ipconfig /all in a command prompt (combine Host Name and Primary Dns Suffix).
Instead of “IT” and “mycompany” enter your department and company name respectively.
Instead of “Zurich”, “ZH” and “CH” enter the city, state (or Kanton or Bundesland or region or whatever) and country respectively.
Under “Alternative Name”:
Change the type to “IP Address (v4)” and in the Value field type “127.0.0.1”. Click “Add”.
Change the type to “DNS” and in the Value field type the following, clicking “Add” every time:
localhost
ch-zh-jim-01 (i.e. the server name without the default domain)
jim.mycompany.com (i.e. the alias that will be normally used)
(add as many names as needed)
Important note: all names you enter there must be resolvable (i.e. there’s a DNS entry for the name) by the CA that will generate your certificate. Otherwise there’s no way they can confirm you’re telling the truth and the request will most likely be rejected.
It should end up looking like this:
In the “Extensions” tab, expand “Extended Key Usage (application policies)”. Select “Server Authentication” and “Client Authentication” and click “Add”.
In the “Private Key” tab, expand “Key Options”.
Set the “Key Size” to 2048 (recommended) or higher.
Check the “Mark private key exportable” check box.
(optional, but HIGHLY recommended) Check the “Strong private key protection” check box. This will make the process ask for a certificate password. Avoid only if your software doesn’t support this (although if it does, you really should question if you should be using it!).
At the end, click OK, then Next. Provide a password (make sure you keep it somewhere safe NOT ON A TEXT FILE ON YOUR DESKTOP, YOU KNOW THAT RIGHT???) and save the CSR file. That’s what you have to send to your CA, according to their instuctions.
B. Using Java
Here the process is sooo much simpler:
Open a command prompt (I’m assuming your Java/bin is in the system path; if not, cd to the bin directory of your Java installation). You should have enough permissions to write to your Java security dir; in Windows, that means that you need an administrative command prompt.
Create the certificate. Type the following, in one line, but given here splitted for clarity. Replace as explained below.
“cert-jim-05-2021”, both in the filename and the alias, with your certificate name (which is the short name for your certificate; this has nothing to do with the server itself).
“ch-zh-jim-01.mycompany.local” with the full DNS name of your server.
“IT” and “mycompany” with your department and company name respectively.
“Zurich”, “ZH” and “CH” with your city, state (or Kanton or Bundesland or region or whatever) and country respectively.
“ch-zh-jim-01” with your server name (without the domain name).
“jim.mycompany.com” with the DNS alias you’re using. You can add as many as needed, e.g. “DNS:jim.mycompany.com,DNS:jim-server.mycompany.com,DNS:jim.mycompany.gr,DNS:jim.mycompany.ch”
Important note: all names you enter there must be resolvable (i.e. there’s a DNS entry for the name) by the CA that will generate your certificate. Otherwise there’s no way they can confirm you’re telling the truth and the request will most likely be rejected.
“changeit” is the default password of the Java certificate store (JAVA_HOME/jre/lib/security/cacerts). It should be replaced by the actual password of the certificate store you’re using. But 99.999% of all java installations never get this changed 😊 so if you don’t know otherwise, leave it as it is.
“MYSUPERSECRETPASSWORD” is a password for the certificate. Make sure you keep it somewhere safe NOT ON A TEXT FILE ON YOUR DESKTOP, YOU KNOW THAT RIGHT???
That’s it. The CSR is saved in the path you specified (in the “-file” option). That’s what you have to send to your CA, according to their instuctions.
A good part of my job has to do with enterprise messaging. When a piece of data -a message- needs to be sent from, say, an invoicing system to an accounting system and then to a customer relationship system and then to the customer portal… it has to navigate treacherous waters.
Avast ye bilge-sucking scurvy dogs! A JSON message from accounting says they hornswaggled 1000 doubloons! Aarrr!!!
So we need to make sure that whatever happens, say if a system is overloaded while receiving the message, the message will not be lost.
A key component in this is message queues (MQ), like RabbitMQ. An MQ plays the middleman; it receives a message from a system and stores it reliably until the next system has confirmed that it picked it up.
My daily duties includes setting up, configuring and maintaining a few RabbitMQ instances. It works great! Honestly, so far -for loads up to a couple of 100s of messages per second- I haven’t even had the need to do any serious tuning.
But one thing that annoys me on Windows is that, after installation, the location of everything except the binaries -configuration, data, logs- is under the profile dir of the user (C:\Users\USERNAME\AppData\Roaming\RabbitMQ) that did the installation, even if the service runs as LocalSystem. Not very good, is it?
Therefore I’ve created this script to help me. The easiest way to use it is run it before you install RabbitMQ. Change the directories in this part and run it from an admin powershell:
Then just reboot and run the installation normally; when it starts, RabbitMQ will use the directories you specified.
You can also do it after installation, if you have a running instance and want to move it. In this case do the following (you can find these steps also in the script):
Stop the RabbitMQ service.
From Task Manager, kill the epmd.exe process if present.
Go to the existing base dir (usually C:\Users\USERNAME\AppData\Roaming\RabbitMQ) and move it somewhere else (say, C:\temp).
Run this script (don’t forget to change the paths).
Reboot the machine
Run the “RabbitMQ Service (re)install” (from Start Menu).
Copy the contents of the old log dir to $LogLocation.
Copy the contents of the old db dir to $DbLocation.
Copy the files on the root of the old base dir (e.g. advanced.config, enabled_plugins) to $BaseLocation.
Start the RabbitMQ service.
Here’s the script. Have fun 🙂
#
# Source: DotJim blog (http://dandraka.com)
# Jim Andrakakis, March 2021
#
# What this script does is:
# 1. Creates the directories where the configuration, queue data and logs will be stored.
# 2. Downloads a sample configuration file (it's necessary to have one).
# 3. Sets the necessary environment variables.
# If you're doing this before installation:
# Just run it, reboot and then install RabbitMQ.
# If you're doing this after installation, i.e. if you have a
# running service and want to move its files:
# 1. Stop the RabbitMQ service
# 2. From Task Manager, kill the epmd.exe process if present
# 3. Go to the existing base dir (usually C:\Users\USERNAME\AppData\Roaming\RabbitMQ)
# and move it somewhere else (say, C:\temp).
# 4. Run this script.
# 5. Reboot the machine
# 6. Run the "RabbitMQ Service (re)install" (from Start Menu)
# 7. Copy the contents of the old log dir to $LogLocation.
# 8. Copy the contents of the old db dir to $DbLocation.
# 9. Copy the files on the root of the old base dir (e.g. advanced.config, enabled_plugins)
# to $BaseLocation.
# 10. Start the RabbitMQ service.
# ========== Customize here ==========
$BaseLocation = "C:\mqroot\conf"
$DbLocation = "C:\mqroot\db"
$LogLocation = "C:\mqroot\log"
# ====================================
$exampleConfUrl = "https://raw.githubusercontent.com/rabbitmq/rabbitmq-server/master/deps/rabbit/docs/rabbitmq.conf.example"
Clear-Host
$ErrorActionPreference = "Stop"
$dirList = @($BaseLocation, $DbLocation, $LogLocation)
foreach($dir in $dirList) {
if (-not (Test-Path -Path $dir)) {
New-Item -ItemType Directory -Path $dir
}
}
# If this fails (e.g. because there's a firewall) you have to download the file
# from $exampleConfUrl manually and copy it to $BaseLocation\rabbitmq.conf
try {
Invoke-WebRequest -Uri $exampleConfUrl -OutFile ([System.IO.Path]::Combine($BaseLocation, "rabbitmq.conf"))
}
catch {
Write-Host "(!) Download of conf file failed. Please download the file manually and copy it to $BaseLocation\rabbitmq.conf"
Write-Host "(!) Url: $exampleConfUrl"
}
&setx /M RABBITMQ_BASE $BaseLocation
&setx /M RABBITMQ_CONFIG_FILE "$BaseLocation\rabbitmq"
&setx /M RABBITMQ_MNESIA_BASE $DbLocation
&setx /M RABBITMQ_LOG_BASE $LogLocation
Write-Host "Finished. Now you can install RabbitMQ."
I just published a new version of my open source C# XmlSlurper library in Github and Nuget.org.
The new version, 1.3.0, contains two major bug fixes:
In previous versions, when the xml contained CDATA nodes, an error was thrown (“Type System.Xml.XmlCDataSection is not supported”). This has been fixed, so now the following works:
<CustomAttributes>
<Title><![CDATA[DOCUMENTO N. 1234-9876]]></Title>
</CustomAttributes>
This xml can be used as follows:
var cdata = XmlSlurper.ParseText(getFile("CData.xml"));
Console.WriteLine(cdata.Title);
// produces 'DOCUMENTO N. 1234-9876'
In previous versions, when the xml contained xml comments, an error was thrown (“Type System.Xml.XmlComment is not supported”). This has been fixed; the xml comments are now ignored.
Separately, there are a few more changes that don’t impact the users of the library:
A Github action was added that, when the package version changes, automatically builds and tests the project, creates a Nuget package and publishes it to Nuget.org. That will save me quite some time come next version 🙂
The test project was migrated from DotNet Core 2.2 to 3.1.
The tests were migrated from MSTest to xUnit, to make the project able to be developed both in Windows and in Linux -my personal laptop runs Ubuntu.
The new version is backwards compatible with all previous versions. So if you use it, updating your projects is effortless and strongly recommended.
When your SQL Server DB log files are growing and your disk is close to being full (or, as it happened this morning, fill up completely thus preventing any DB operation whatsoever, bringing the affected system down!) you need to shrink them.
What this means, basically, is that you create a backup (do NOT skip that!) and then you delete information that allows you to recover the database to any point in time before the backup. That’s what SET RECOVERY SIMPLE & DBCC SHRINKFILE do. And since you kept a backup, you no longer need this information. You don’t need it for operations after the backup though, that’s why we go back to full recovery mode with SET RECOVERY FULL at the end.
So what you need is to login to your SQL Server with admin rights and:
USE DatabaseName
GO
BACKUP DATABASE DatabaseName
TO DISK = 'C:\dbbackup\DatabaseName.bak'
WITH FORMAT,
MEDIANAME = 'DatabaseNameBackups',
NAME = 'Full Backup of DatabaseName';
GO
ALTER DATABASE DatabaseName SET RECOVERY SIMPLE;
GO
CHECKPOINT;
GO
DBCC SHRINKFILE ('DatabaseName_Log', 10);
GO
ALTER DATABASE DatabaseName SET RECOVERY FULL;
GO
Notice the 10 there -that’s the size, in MB, that the DB Log file will shrink to. You probably need to change that to match your DB needs. Also, the DatabaseName_Log is the logical name of your DB Log. You can find it in the DB properties. You probably also need to change the backup path from the example C:\dbbackup\DatabaseName.bak.
I’m not a fan of IT hubris. I cringe -literally- when I hear stuff like “let’s fight cancer (or whatever) with scrum”. You don’t fight diseases with IT; at best, you can help.
But help can be important. One problem that IT is very well suited to solve is understanding how viruses and bacteria behave under certain circumstances. The Folding@Home project explains:
WHAT IS PROTEIN FOLDING AND HOW IS IT RELATED TO DISEASE? Proteins are necklaces of amino acids, long chain molecules. They are the basis of how biology gets things done. As enzymes, they are the driving force behind all of the biochemical reactions that make biology work. As structural elements, they are the main constituent of our bones, muscles, hair, skin and blood vessels. As antibodies, they recognize invading elements and allow the immune system to get rid of the unwanted invaders. For these reasons, scientists have sequenced the human genome – the blueprint for all of the proteins in biology – but how can we understand what these proteins do and how they work?
However, only knowing this sequence tells us little about what the protein does and how it does it. In order to carry out their function (e.g. as enzymes or antibodies), they must take on a particular shape, also known as a “fold.” Thus, proteins are truly amazing machines: before they do their work, they assemble themselves! This self-assembly is called “folding.”
WHAT HAPPENS IF PROTEINS DON’T FOLD CORRECTLY? Diseases such as Alzheimer’s disease, Huntington’s disease, cystic fibrosis, BSE (Mad Cow disease), an inherited form of emphysema, and even many cancers are believed to result from protein misfolding. When proteins misfold, they can clump together (“aggregate”). These clumps can often gather in the brain, where they are believed to cause the symptoms of Mad Cow or Alzheimer’s disease.
The project has made it very easy for anyone to help. You just download and install their software, and your computer starts calculating, solving math problems -essentially, you’re giving your computer’s processing power when you don’t use it. You can see your -and other’s- contribution in the project stats.
I heartily encourage you to do so.
That’s my HP i7, sitting in the attic and doing what little it can to help beat COVID19.
I’ve written before an example on how to use Powershell and FetchXml to get records from a Dynamics CRM instance. But there’s a limit, by default 5000 records, on how many records CRM returns in a single batch -and for good reason. There are many blog posts out there on how to increase the limit or even turn it off completely but this is missing the point: you really really really don’t want tens or hundreds of thousand -or, god forbid, millions- of records being returned in a single operation. That would probably fail for a number of reasons, not to mention it would slow the whole system to a crawl for a very long time!
So we really should do it the right way, which is to use paging. It’s not even hard! It’s basically almost the same thing, you just need to add a loop.
That’s the code I wrote to update all active records (the filter is in the FetchXml, so you can just create yours and the code doesn’t change). I added a progress indicator so that I get a sense of performance.
#
# Source: DotJim blog (http://dandraka.com)
# Jim Andrakakis, June 2020
#
# Prerequisites:
# 1. Install PS modules
# Run the following in a powershell with admin permissions:
# Install-Module -Name Microsoft.Xrm.Tooling.CrmConnector.PowerShell
# Install-Module -Name Microsoft.Xrm.Data.PowerShell -AllowClobber
#
# 2. Write password file
# Run the following and enter your user's password when prompted:
# Read-Host -assecurestring | convertfrom-securestring | out-file C:\usr\crm\crmcred.pwd
#
# ============ Constants to change ============
$pwdFile = "C:\usr\crm\crmcred.pwd"
$username = "myuser@mycompany.com"
$serverurl = "https://myinstance.crm4.dynamics.com"
$fetchxml = "C:\usr\crm\all_active.xml"
# =============================================
Clear-Host
$ErrorActionPreference = "Stop"
# ============ Login to MS CRM ============
$password = get-content $pwdFile | convertto-securestring
$cred = new-object -typename System.Management.Automation.PSCredential -argumentlist $username,$password
try
{
$connection = Connect-CRMOnline -Credential $cred -ServerUrl $serverurl
}
catch
{
Write-Host $_.Exception.Message
exit
}
if($connection.IsReady -ne $True)
{
$errorDescr = $connection.LastCrmError
Write-Host "Connection not established: $errorDescr"
exit
}
else
{
Write-Host "Connection to $($connection.ConnectedOrgFriendlyName) successful"
}
# ============ Fetch data ============
[string]$fetchXmlStr = Get-Content -Path $fetchxml
$list = New-Object System.Collections.ArrayList
# Be careful, NOT zero!
$pageNumber = 1
$pageCookie = ''
$nextPage = $true
$StartDate1=Get-Date
while($nextPage)
{
if ($pageNumber -eq 1) {
$result = Get-CrmRecordsByFetch -conn $connection -Fetch $fetchXmlStr
}
else {
$result = Get-CrmRecordsByFetch -conn $connection -Fetch $fetchXmlStr -PageNumber $pageNumber -PageCookie $pageCookie
}
$EndDate1=Get-Date
$ts1 = New-TimeSpan –Start $StartDate1 –End $EndDate1
$list.AddRange($result.CrmRecords)
Write-Host "Fetched $($list.Count) records in $($ts1.TotalSeconds) sec"
$pageNumber = $pageNumber + 1
$pageCookie = $result.PagingCookie
$nextPage = $result.NextPage
}
# ============ Update records ============
$StartDate2=Get-Date
$i = 0
foreach($rec in $list) {
$crmId = $rec.accountid
$entity = New-Object Microsoft.Xrm.Sdk.Entity("account")
$entity.Id = [Guid]::Parse($crmId)
$entity.Attributes["somestringfieldname"] = "somevalue"
$entity.Attributes["somedatefieldname"] = [datetime]([DateTime]::Now.ToString("u"))
$connection.Update($entity)
$i = $i+1
# this shows progress and time every 1000 records
if (($i % 1000) -eq 0) {
$EndDate2=Get-Date
$ts2 = New-TimeSpan –Start $StartDate2 –End $EndDate2
Write-Host "Updating $i / $($list.Count) in $($ts2.TotalSeconds) sec"
}
}
$EndDate2=Get-Date
$ts2 = New-TimeSpan –Start $StartDate2 –End $EndDate2
Write-Host "Updated $($list.Count) records in $($ts2.TotalSeconds) sec"
For my purposes I used the following FetchXml. You can customize it or use CRM’s advanced filter to create yours:
Something to keep in mind here is to minimize the amount of data being queried from CRM’s database and then downloaded. Since we’re talking about a lot of records, it’s wise to check your FetchXml and eliminate all fields that are not needed.
Some time ago, a friend of mine (the one of “How I fought off a Facebook hacker” fame) had problems with his Windows laptop, basically the machine became next to useless. Sadly, while I generally like Windows (there are exceptions) this is something that happens all too often. So I solved it by installing Ubuntu, and even though he’s not technically proficient he’s very happy -the machine isn’t exactly lightning fast, but it works and it’s stable.
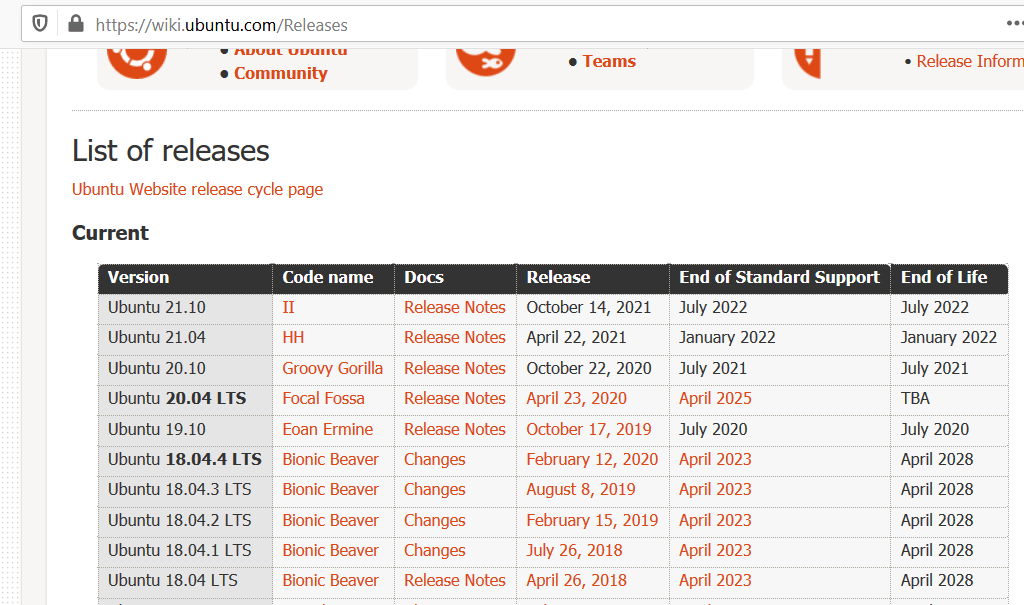
But a small mistake I made was installing the latest-greatest Ubuntu version available at the time, 19.04. Now for those who don’t know, Ubuntu has some releases that are supported for a long time, called LTS for Long Term Support, and the ones in between that are… not. Full list here.
So as of January 2020, 19.04 went into End-Of-Life status, meaning you can’t download and install updates the normal way (apt upgrade) any more. And without updates, you can’t upgrade to a newer release (do-release-upgrade) as well. The first symptom is that, while trying to install updates, he was getting errors similar to the following:
E: Unable to locate package XXX
An additional problem is that we’re in different countries, so I couldn’t just do the usual routine backup-format-reinstall everything 🙂
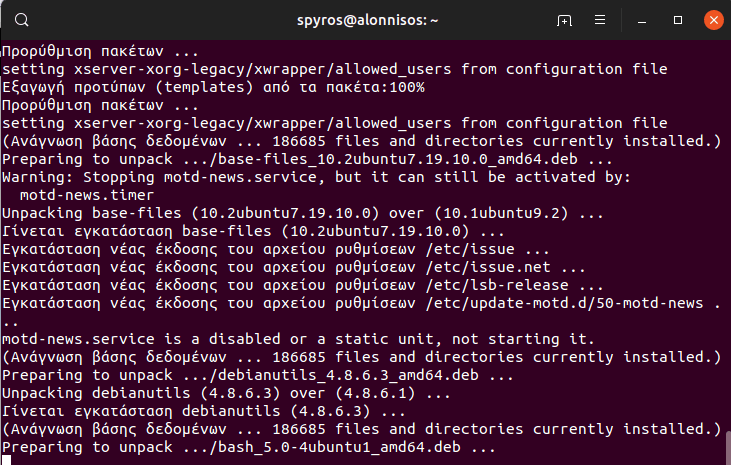
But as usual, Google is your friend! That’s how I solved it from the command line:
sudo sed -i -re 's/([a-z]{2}\.)?archive.ubuntu.com|security.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
sudo apt update
sudo apt upgrade
# ...wait for like 30min, then restart...
sudo do-release-upgrade
# ...wait for a couple of hours, restart
What does this do? Well everything except the first line is the standard procedure to upgrade: update (i.e. refresh info for) the software repositories, upgrade (i.e. download and install the updates), restart and then do-release-upgrade which upgrades the complete Ubuntu system -always to the latest LTS release.
But the “magic” is in the first line (and let’s give credit where it’s due). This changes the list that keeps the repositories location (/etc/apt/sources.list) from the normal locations (under archive.ubuntu.com or security.ubuntu.com) to the “historic” servers, old-releases.ubuntu.com. For more info, see “Update sources.list” here.
So after that is done, apt upgrade can now install whatever updates are available and then do-release-upgrade can do its job.
Software, Greece, Switzerland. And coffee. LOTS of coffee !